
Кейс-стаді: семантична сегментація в прикладах і деталях


Семантична сегментація — це потужна техніка, яка зробила революцію в багатьох галузях, включаючи медичну візуалізацію, автономне водіння та виявлення об’єктів. Це дозволяє комп’ютерам розуміти вміст зображення на піксельному рівні, розділяючи його на значущі регіони та призначаючи мітки кожному з них. Ця технологія відкрила нові можливості для багатьох галузей промисловості, даючи їм змогу автоматизувати складні завдання, підвищити точність і заощадити час і ресурси.
У цій статті ми дослідимо світ семантичної сегментації на реальних прикладах і кейсах. Ми заглибимося в основи семантичної сегментації, використовувані техніки та алгоритми, а також проблеми та обмеження цієї технології. Ми також розглянемо три різні тематичні дослідження, які демонструють різноманітні застосування семантичної сегментації в медичній візуалізації, автономному керуванні автомобілем і виявленні об’єктів.
Нарешті, ми обговоримо майбутнє семантичної сегментації та її потенціал для подальшого прогресу та розвитку. Приєднуйтесь до нас у цій інформативній подорожі, щоб дізнатися більше про семантичну сегментацію та її застосування в реальному світі.
Вступ до семантичної сегментації
Семантична сегментація — це завдання комп’ютерного зору, яке передбачає призначення мітки кожному пікселю зображення. Цю техніку можна використовувати в різних сферах, таких як автономне водіння, розпізнавання об’єктів і медична візуалізація. Семантична сегментація має на меті класифікувати всі об’єкти сцени та групувати пікселі, які належать до одного класу. Це відрізняється від сегментації екземплярів, яка розрізняє кілька екземплярів одного класу.
Методи глибокого навчання виявилися дуже ефективними для семантичної сегментації, особливо з даними дистанційного зондування. Однак більшість найсучасніших підходів покладаються на навчання під наглядом із використанням створених вручну наборів функцій. Навчальні дані часто включають великі набори даних із мітками на рівні пікселів, які вимагають значних зусиль для анотації.
Поряд з популярними архітектурами глибокого навчання, такими як U-net і FCN (повністю згорткові мережі), дослідники також досліджували різні підходи, включаючи гібридні мережі для мультимодального об’єднання даних, механізми уваги для коригування ваги щодо значущості функцій і використання попередня інформація про форми та розміри об’єктів під час попередньої обробки.
Семантична сегментація набула обертів в останні роки завдяки широкому застосуванню не тільки в системах штучного інтелекту, але й актуальному для багатьох інших областей, включаючи цифровий маркетинг і міське планування. У той час як методи глибокого навчання продовжують розвивати більш витончені способи обробки величезних наборів даних або ефективної обробки великих обсягів зображень разом із менш контрольованим підходом, використовуючи доступні характеристики набору даних для напівконтрольованого або навіть неконтрольованого умовного кластеризування чи сортування; враховуючи ці сукупні фактори, ймовірно, що інноваційні розробки продовжаться в осяжному майбутньому, тим самим підвищуючи ефективність обчислень у різних галузях, відкриваючи шлях для бізнес-випадків наступного покоління в різних географічних регіонах і на різних ринках.
Розуміння основ семантичної сегментації
Семантична сегментація — це техніка комп’ютерного зору, яка передбачає позначення та сегментування кожного пікселя зображення на основі його семантичного вмісту. Ця технологія широко використовується в різних сферах, таких як дистанційне зондування, автономні транспортні засоби та медична візуалізація. Традиційні методи сегментації мають деякі обмеження щодо точності меж об’єктів і виявлення малих або складних об’єктів. Однак алгоритми Deep Learning забезпечують наскрізну семантичну сегментацію робочих процесів, що призвело до значного прогресу в цій галузі.
Один із поширених методів семантичної сегментації називається архітектурою кодера-декодера, яка складається з двох основних компонентів: мереж кодера та декодера. Мережа кодера стискає вхідне зображення в простір ознак нижчого розміру послідовними згортковими шарами. Тим часом мережа декодера приймає це представлення ознак як вхідні дані та генерує вихідну карту сегментації з попіксельними мітками для кожного класу об’єктів. Існує декілька варіантів цієї архітектури з різними зв’язками пропуску між відповідними рівнями частин кодування та декодування.
Ця техніка має кілька застосувань у сценаріях реального світу. Наприклад, семантична сегментація смуг для кількох класів є особливою проблемою, з якою стикаються під час створення систем допомоги водієві для автономних автомобілів або розширених систем допомоги водієві (ADAS), які призводять до суттєвих покращень безпечного керування автомобілем.
Семантична сегментація відіграє життєво важливу роль у багатьох сферах, де потрібне точне піксельне маркування. Оскільки щодня розробляються кращі моделі глибокого навчання, немає сумнівів, що семантична сегментація й надалі залишатиметься одним із найважливіших завдань маркування даних для програм комп’ютерного зору.
Приклад 1: семантична сегментація в медичній візуалізації
У сфері медичної візуалізації семантична сегментація використовується для перевірки росту органів, захворювань або аномалій на зображеннях. Останні досягнення в повністю згорткових мережах уможливили автоматичну сегментацію за допомогою глибоких нейронних мереж. Семантична сегментація зробила революцію в галузі, спростивши вилучення релевантної інформації зі складних медичних зображень.
Багатовимірні статистичні характеристики використовуються для виділення та об’єднання в сегментації медичних зображень. Ці функції можуть успішно ідентифікувати об’єкти та зони інтересу та виконувати точні автоматизовані вимірювання. Використання цих методів дозволяє швидше встановити діагноз і спланувати лікування, що в кінцевому підсумку призводить до кращих результатів для пацієнтів.
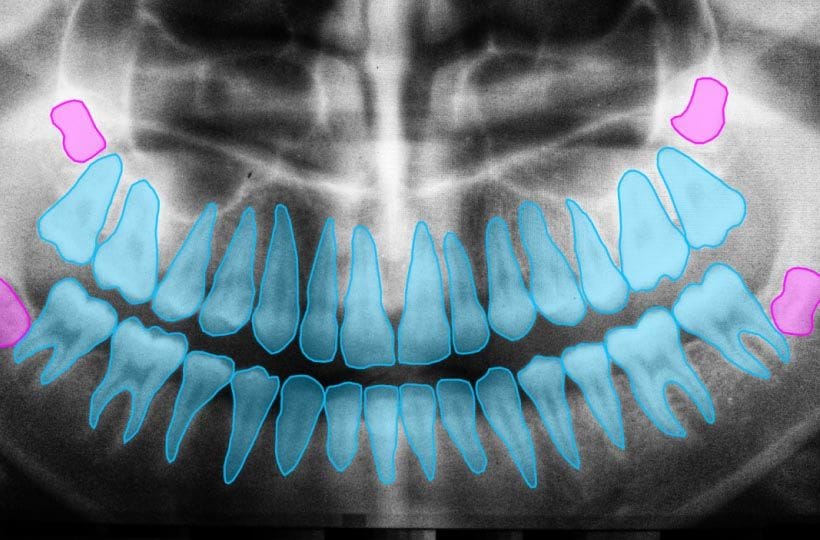
Одним із практичних застосувань семантичної сегментації є ідентифікація пухлин на МРТ. Виділяючи підозрілі ділянки зі здорових тканин мозку, лікарі можуть краще аналізувати та діагностувати такі захворювання, як гліоми або менінгіоми з більшою точністю. Крім того, семантична сегментація знайшла застосування далеко за межами сканування МРТ у ряді медичних процедур, включаючи ендоскопію, рентгенографію та інші.
Семантична сегментація є надзвичайно важливою для медичної візуалізації, оскільки вона покращує швидкість і точність діагностики. Це допомагає лікарям точніше визначати аномальні області та розробляти цільові варіанти лікування для пацієнтів із певними захворюваннями на основі семантичного вмісту, отриманого з наборів даних їхніх медичних зображень, і все це за скорочений часовий проміжок завдяки цьому методу автоматизації за допомогою моделей машинного навчання, таких як повністю згорточні нейронні мережі.
Приклад 2: Семантична сегментація в автономному водінні
Семантична сегментація є життєво важливою задачею сприйняття в автономному керуванні. Він передбачає ідентифікацію об’єктів та їхніх меж на зображенні, що допомагає транспортному засобу зрозуміти оточення. LiDAR і камера — це два способи, які використовуються для 3D-семантичної сегментації в автономному водінні. Щоб безпілотні транспортні засоби точно сприймали навколишнє середовище, потрібні різні модальності.
Кілька архітектур глибокого навчання, таких як згорткові нейронні мережі та автокодери, використовувалися для розробки моделей семантичної сегментації в автономних транспортних засобах. Глибокі мережі, засновані на перехресних втратах ентропії, досягли прогресу із середнім перетином через об’єднання.
Дослідження показують, що більшість досліджень семантичної сегментації зосереджені виключно на підвищенні точності, при цьому менше уваги приділяється обчислювально ефективним рішенням. Тому існує потреба оцінити різні моделі з використанням різних модальностей, доступних для тривимірної семантичної сегментації в автономному керуванні.
Змагальні атаки на семантичну сегментацію на основі LiDAR можуть бути легко здійснені хакерами, які вводять змагальний шум у вхідні дані моделі та змушують її неправильно класифікувати об’єкти або взагалі припиняти роботу. Тому при розробці цих моделей для використання в системах автономного водіння важливо застосовувати відповідний захист від таких атак.

Приклад 3: семантична сегментація при виявленні об’єктів
Семантична сегментація є ключовим завданням комп’ютерного зору, яке дозволяє машинам розуміти та аналізувати зображення та відео на піксельному рівні. Сучасні методи використовують багатозадачне навчання для оцінки глибини та семантичної сегментації, що продемонструвало значне покращення перцептивного розуміння. Згорткові нейронні мережі (CNN) і трансформатори бачення є популярними моделями архітектури, які використовуються для семантичної сегментації.
Спільне виявлення об’єктів і семантична сегментація необхідні для таких програм, як автономне водіння, редагування зображень і робототехніка. Основна проблема поєднання цих завдань полягає в тому, щоб зв’язати семантичну сегментацію з виявленням екземплярів об’єктів для точного визначення місця розташування об’єктів на зображенні. Мережі для семантичної сегментації зазвичай складаються з кодера для виділення ознак і декодера для щільної класифікації пікселів.
Навчання CNN для семантичної сегментації вимагає високоякісних даних, але рідкісні об’єкти можуть вплинути на стабільність і точність передбачення. Щоб вирішити цю проблему, дослідники запропонували стратегії навчання, засновані на генеративних змагальних мережах (GAN), які дозволяють мережі генерувати синтетичні дані, подібні до сценаріїв реального світу.
Сьогодні семантична сегментація в поєднанні з виявленням об’єктів має численні застосування в різних сферах. CNN і трансформатори Vision є популярними архітектурними моделями, які використовуються в цьому підході, які поєднують методології глибокого навчання та багатозадачні режими навчання, які забезпечують чудові результати з надійними показниками точності навіть перед обличчям рідкісних проблем прогнозування об’єктів, що спричиняє спотворення результатів від інших архітектур CNN, недостатньо придатних для обробки винятки відсутніх даних, які зазвичай зустрічаються в сегментованих наборах даних.
Техніки та алгоритми, що використовуються в семантичній сегментації
Семантична сегментація — це завдання класифікації, яке витягує значущу інформацію із зображень або вхідних кадрів у відео або записах. Цей процес складається з трьох етапів: класифікації, локалізації та сегментації. Існує два основних типи техніки сегментації: сегментація екземплярів і семантична сегментація. Семантична сегментація стосується позначення кожного пікселя зображення міткою класу з попередньо визначеного набору класів.
Було розроблено багато підходів для семантичної сегментації, включаючи традиційні методи з використанням методів на основі порогових значень і методів на основі глибокого навчання. Традиційні методи включають виділення ознак із зображення та подальшу класифікацію пікселів. Однак підходи, засновані на глибокому навчанні, перевершують традиційні методи, використовуючи величезні обсяги позначених даних для вивчення складних моделей, які поводяться по-різному залежно від різних функцій зображення.
Алгоритм семантичної сегментації SageMaker від Amazon забезпечує високоточне автоматизоване рішення для цього завдання, коли мітки на рівні пікселів можна передбачувано генерувати в режимі реального часу за допомогою обробки машинного навчання в масштабованих середовищах хмарних обчислень, таких як Amazon Web Services (AWS). Перевага цієї методики полягає в тому, що вона вимагає мінімальних зусиль порівняно з традиційними методами, забезпечуючи високоточні результати.
Семантична сегментація має важливе значення для завдань комп’ютерного зору, таких як розпізнавання об’єктів, автономне водіння автомобілів, діагностика медичних зображень, наприклад КТ та МРТ, серед інших. Методи, що використовуються в семантичній сегментації, можуть бути як традиційними (на основі порогових значень), так і більш просунутими алгоритмами глибокого навчання, які зараз доступні, як-от ті, що пропонуються платформою Amazon SageMaker, що забезпечує доступні масштабовані рішення з високою точністю, незалежно від великих складних наборів даних у різних доменах, як-от роздрібна торгівля. платформи мобільних додатків, які обслуговують додатки для створення журналів моди в режимі реального часу, які обслуговують віртуальні вбрання, стилізовані на фотографіях користувачів, або науки про здоров’я, які виконують ультразвукове виявлення аномалій шляхом автоматизованого вибору аномалій печінки для секретних передніх планів!
Проблеми та обмеження семантичної сегментації
Семантична сегментація є потужною технікою аналізу зображень із такими додатками, як автономне водіння, аналіз медичних зображень і аналіз покриття землі. Однак ця методика створює проблеми та обмеження в певних областях. Наприклад, аналіз коралів викликає труднощі через складну морфологію цих форм життя. Традиційні методи комп’ютерного зору мають обмеження щодо виявлення кількох типів дефектів і отримання сегментації на рівні пікселів.
Глибоке навчання довело ефективність в обробці зображень дистанційного зондування завдяки своїй здатності автоматично отримувати релевантні функції з великих обсягів даних. Було запропоновано кілька методів семантичної сегментації на основі глибокого навчання, які добре працюють навіть за наявності тонких структур. Однак методи глибокого навчання схильні до проблем, властивих класовому дисбалансу, які можуть погіршити продуктивність.
Архітектурні моделі, такі як CNN і ViT, забезпечують ефективні результати завдань семантичної сегментації для різних завдань, включаючи аналіз медичного зображення та автономне водіння. В останні роки зростає інтерес до сегментації низькоканальних придорожніх даних 3D LiDAR. Для семантичної сегментації придорожнього 3D LiDAR було представлено новий метод на основі зрізів, який ефективно долає деякі обмеження за допомогою інформації, отриманої на різних висотах.
Незважаючи на труднощі, пов’язані з певними областями, семантична сегментація залишається важливим інструментом для отримання значущої інформації з даних зображень завдяки своїй універсальності в багатьох галузях, починаючи від геології, сільськогосподарських досліджень і медицини.
Майбутні застосування та розробки семантичної сегментації
Мультимодальне злиття даних прокладає шлях для нових розробок у семантичній сегментації. Цей напрямок досліджень показав великі перспективи для підвищення ефективності сегментації шляхом використання взаємодоповнюючих переваг різних модальностей. Дані з таких джерел, як LiDAR, камери RGB і теплові камери, можна поєднувати, щоб створити більш повні та детальніші анотації.
Іншим напрямком розвитку семантичної сегментації є розумний транспорт. Оскільки автономні транспортні засоби стають все більш поширеними, їм потрібні точні та ефективні системи сприйняття для інтерпретації навколишнього середовища. Семантична сегментація відіграє вирішальну роль у цьому процесі, дозволяючи машинам розуміти й аналізувати візуальні дані.
Незважаючи на свою важливість, розробка ефективних моделей семантичної сегментації залишається проблемою. Традиційні конструкції кодера-декодера широко використовуються, але часто виникають труднощі з обробкою складних або перекриваючих об’єктів. Дослідники досліджують альтернативні підходи, такі як адаптація трансформаторних мереж або включення механізмів уваги.
Досягнення мультимодального об’єднання даних, інтелектуальної транспортної технології та архітектури моделей продовжуватимуть впливати на розвиток семантичної сегментації. Ці рішення мають вирішальне значення не тільки для підвищення точності, але й для досягнення реальних додатків, які можуть принести користь суспільству в цілому.